技術の価格 (機械学習を題材に)
機械学習自体は1960年代からずっと研究されており、何回かブームがあった事は様々な記事で指摘されている通りだが(例:Over the AI - AIの向こう側に)、
最近の流行はとどまるところを知らない。2010年代後半に入って、Keras/TensorFlow
やscikit-learn等の機械学習のフレームワークが整ってきたため、
最先端のアルゴリズムを自前で実装しなければならない場合で無ければ、
基本的に、統計処理のソフトと同程度の勉強量で、実際のデータを機械学習で処理することができるようになってきた。mac OSは色々な技術をどんどん取り込むことで有名で、
macOS High Sierra (10.13)ではCore MLとして、macOS Mojave (10.14)ではCreate MLとして、機械学習のフレームワークが追加されており、
比較的容易に機械学習を利用できる。Windowsはその点フレームワークとしての整備は遅いが、
Visual Studioでは2017あたりからはPythonのanacondaインストールと開発が出来るようになっており、機械学習の利用に関しては大きな差はない。
Appleがあくまでエコシステムを強化するために、最新の技術を自分のものとしてmac OS環境内の独自のライブラリを構築するのに対し、Windowsはオープンソースの方向を向いていると言えるかもしれない。
もっとも、昨今のオープンソースのプロジェクトのうち大きなものの多くは、大企業の従業員がメンテナンスしていることが多く、無償という面が強調されやすいオープンソースというよりは、
集合知としてのオープンシステムと言った方が適切かもしれない。Windows内にLinuxのサブシステム(debian)を用意するようになったのも、同じ流れによるものだろう。
機械学習の流行にのって、インターネット上で学習をするサイトや一般人向けの有料学習講座が雨後の筍の様に増えており、機械学習そのものが一大産業となりつつあるようにも見える。
習得したい人にとってはいくらでも情報を得られるが、そうでない人は取り残されやすい、比較的競争の厳しい世界になっている。もっとも、技術を習得したからといって、
すぐによい職にありつけたり転職できたりするわけでもなく、技術が対価としてすぐに評価されるという期待は往々にして裏切られることが多い。
古くから機械学習が応用されていた分野の一つに自然言語処理が挙げられ、検索サイトの構築の基盤技術となっているが、これは、次元が比較的低く済んでいたこともあるが、
機械学習に入力するデータが、もともと豊富にあり、容易に得られやすかったことも一つにあるだろう。
機械学習自体は単なるアルゴリズムであり、データから何らかの対応を導き出すだけであり、適当なデータからは適当な結果しか得られず、学習データの精度・質が最も重要であることは以前から知られている。
自然言語処理においては、新聞や論文の文字データ自体等、質の良いデータが得られやすいが、それ以外の、例えば画像処理等の分野では、単純にデータを採取した場合、ゴミを伴ったデータが得られることが多く、意外と困難である。
医療の分野においては、ディープラーニングの学習速度がGPUの速度の高速化に伴って飛躍的に向上したことから、特に内視鏡やCT・MRI等のモダリティにおける画像診断を対象とした研究が盛んとなっているが、
データの収集にはそれなりの労力が必要であり、データ精度を保証する作業量も必要となる。
医学研究をするのに必要な資格はないので、基本的に志のある人たちが行っているわけで、ある程度は無償の労力が費やされているわけだが、最近の研究発表を探していて、技術の価格について考える場面があったので、挙げてみたい。
機械学習によるマンモグラフィの自動判定
マンモグラフィーは、乳がんの検診で使われている画像診断の一つで、白黒の画像から悪性の有無を判断する。
この分野の機械学習では、湘南記念病院の井上謙一先生が有名のようで、様々な記事が見つかる。折角なので、抄録を一つ挙げてみる。
この抄録では、方法が再現可能な程度の詳細さで記述されており、非常に好感が持てる。ちなみに、後述のいくつかの研究報告では、重要な部分が全く記されておらず、再現は不能である。
第26回日本乳癌学会学術総会 2018年5月16日
SY-2-09-5
ディープラーニングを用いたマンモグラフィの自動判定に関する多施設共同研究の取り組み
1湘南記念病院 乳がんセンター、2聖マリアンナ医科大学 乳腺・内分泌外科、 3東海大学医学部 乳腺・内分泌外科、
4特定非営利活動法人神奈川乳癌研究グループ KBOG(Kanagawa Breast Oncology Group)
井上 謙一1,4、川崎 あいか1、小清水 佳和子1、山中 千草1、土井 卓子1,4、津川 浩一郎2,4、鈴木 育宏3,4、徳田 裕3,4
【背景】人工知能を用いた画像認識は様々な分野で応用されている。医療分野でも特に画像解析に関し様々な研究がなされている。我々は、
マンモグラフィ画像を用いて乳癌の自動判定に関する研究をすすめ、単施設で良好な成績を収めた。そこで多施設共同研究での精度を検証することとした。
【目的】神奈川県内で乳癌治療に関わる、4 大学及びがんセンターを含む 12 医療機関による特定非営利活動法人研究グループ KBOG(Kanagawa Breast Oncology Group) では、
臨床試験を積極的に実施している。様々な医療機関のマンモグラフィ画像に対するモデルの頑健性を検証するため、KBOG で多施設共同研究を開始した。
【対象と方法】KBOG の各医療機関で撮影されたマンモグラフィの内、病理結果が判明している、または臨床的に明らかなマンモグラフィを対象とする。
マンモグラフィを 256 X 256 ピクセルに分割し、背景画像を除いたそれぞれの画像に対し、乳癌が描出されている、良性病変が描出されている、
所見なし、の 3 通りにラベル付けする。これら分割画像を畳み込みニューラルネットワークに入力・教師あり学習させ、精度として正診率、感度、特異度を計測する。
【結果】単施設での研究成績は、画像データ 47282 枚に対し、AlexNet モデルでは正診率 96.6%、感度 93.9%、特異度 99.2%、PPV 99.2%、NPV 94.2%であった。
画像の条件を修正して ResNet モデルで再検証したところ、正診率95.2%、感度 94.7%、特異度 95.7%、PPV95.6%、NPV94.7% であった。
また、この学習モデルを用いてマンモグラフィ画像をスキャンするアルゴリズムも作成して乳癌が疑わしい部分は赤く光るようにし、読影時のサポート機能を持たせた。
【考察】ディープラーニングはデータが増えれば増える程精度が向上するため、多施設共同研究である本研究ではこれ以上の精度を得ることができると推測する。
また、それが証明されれば、将来的には全国規模でどの医療機関でも気軽に使えるようになり、次世代医療としての基盤を構築できる可能性を秘めている。
【結語】ディープラーニングの技術を用いて、マンモグラフィ画像の自動読影モデルを多施設共同研究として立ち上げ、そのシステムを構築した。
今後、更に検証を重ねると共に精度を改善し、全国で利用できるシステムの構築も目指していく。
畳み込みニューラルネットワークは何種類ものアルゴリズムが存在するが、この研究ではAlexNetとResNetを評価したと記載されている。
実際のところは不明であるが、それ以外の方法のアルゴリズムもおそらく試したが、あまり良い結果が得られなかったので記載しなかったと思われる。
AlexNet(論文)は
2010年に発表されたアルゴリズムで、下記のような層となっている。
1 'data' Image Input 227x227x3 images with 'zerocenter' normalization
2 'conv1' Convolution 96 11x11x3 convolutions with stride [4 4] and padding [0 0 0 0]
3 'relu1' ReLU ReLU
4 'norm1' Cross Channel Normalization cross channel normalization with 5 channels per element
5 'pool1' Max Pooling 3x3 max pooling with stride [2 2] and padding [0 0 0 0]
6 'conv2' Convolution 256 5x5x48 convolutions with stride [1 1] and padding [2 2 2 2]
7 'relu2' ReLU ReLU
8 'norm2' Cross Channel Normalization cross channel normalization with 5 channels per element
9 'pool2' Max Pooling 3x3 max pooling with stride [2 2] and padding [0 0 0 0]
10 'conv3' Convolution 384 3x3x256 convolutions with stride [1 1] and padding [1 1 1 1]
11 'relu3' ReLU ReLU
12 'conv4' Convolution 384 3x3x192 convolutions with stride [1 1] and padding [1 1 1 1]
13 'relu4' ReLU ReLU
14 'conv5' Convolution 256 3x3x192 convolutions with stride [1 1] and padding [1 1 1 1]
15 'relu5' ReLU ReLU
16 'pool5' Max Pooling 3x3 max pooling with stride [2 2] and padding [0 0 0 0]
17 'fc6' Fully Connected 4096 fully connected layer
18 'relu6' ReLU ReLU
19 'drop6' Dropout 50% dropout
20 'fc7' Fully Connected 4096 fully connected layer
21 'relu7' ReLU ReLU
22 'drop7' Dropout 50% dropout
23 'fc8' Fully Connected 1000 fully connected layer
24 'prob' Softmax softmax
25 'output' Classification Output crossentropyex with 'tench' and 999 other classes
ResNetは2015年に発表された152層もあるニューラルネットで、コンペでさらに高い性能を出したアルゴリズムである。
上記の抄録からは、イヌやネコといった物体の認識で最も高い性能を出したからといって、疾患の鑑別でも必ず高い性能が出るという訳ではないということが分かる。
臨床データを大量に集めるためには、研究を始める前の倫理申請・データ管理方法の整備、データ収集中のデータ管理・データ前処理、に非常に多大なコストが要するが、
上記の著者のどれで科研費等を検索しても、明確な研究費が記されたものが見つからず、おそらく特定非営利活動法人研究グループ KBOGがその多くの仕事を行っていると推測される。
5万枚近いデータを集めるのには何年かかったのだろうか。データ自体はDICOMで標準化されており、検診センターには定型化されたデータとして保存されていれば、
意外に収集処理は簡単だったのかもしれないが、実際の手順を一度見てみたいものである。
機械学習の処理については、上記程度の枚数であれば、数十万程度のGPUつきPCを用意すれば処理可能であり、現在のインターネット上にあるフレームワークを駆使できる人が一人いれば済むだろう。
マンモグラフィーでなく、センチネルリンパ節の病理の画像診断での評価であるが、札幌医科大学のグループの発表が同じ学会であったので、その抄録を載せる。
このグループの研究では、アルゴリズムはResNetのみの評価となっている。
SY-2-09-6
ディープラーニングを用いたセンチネルリンパ節迅速病理画像診断
1札幌医科大学 消化器・総合、乳腺・内分泌外科、2札幌医科大学 病理学第一講座、3札幌医科大学 病理診断学
中津川 智子1、中津川 宗秀2、九冨 五郎1、島 宏彰1、里見 蕗乃1、長谷川 匡3、鳥越 俊彦2、竹政 伊知朗1
【背景】乳がんにおけるセンチネルリンパ節 (SLN) 術中迅速病理診断は、臨床的腋窩リンパ節転移陰性症例において、腋窩リンパ節郭清の省略を決定するにあ
たり、重要な検査である。しかし、病理医が常駐していない施設では実施が困難であり、手術方法の選択が限られたものとなる。近年、人工知能研究が盛ん
であるが、2012 年の大規模画像認識コンペティション (ILSVRC) においてディープラーニングといわれる機械学習を用いた画像判別モデルがこれまで
の精度を遥かに凌駕して優勝した。さらに 2015 年には人間よりも高い精度で判別できるまでになっている。本研究では、ディープラーニングを用いた画像
判別モデルによって SLN 迅速病理画像診断が可能か検討した。
【方法】凍結切片より作成された SLN 術中迅速病理標本の whole slide image (WSI) から得られたデジタル画像を 224 × 224 ピクセルに分割し、正常リンパ節組織画像と乳
がん転移組織画像約 30,000 枚を画像の回転、反転により 8 倍に増加させたものを教師データとし、ILSVRC '2015 で優勝した 152 層の畳み込みニューラル
ネットワークである ResNet-152 を用いて深層学習を行い、がんと正常を見分ける画像判別モデルを作成した。
【結果】画像判別モデルに未学習画像を判定させた結果、リンパ節ごとの判別率は約 9 割と良好な結果であり、また、がん転
移巣の領域を高い精度で検出可能であった。この結果から、ディープラーニングを用いた画像判別モデルが SLN 術中迅速病理診断において、
病理医の負担軽減や偏在といった問題に貢献できる可能性が示唆された。
おそらく、機械学習を始めて間もない人が行ったために、判別率約9割という曖昧な書き方になっていると思われる。
著者リストには札幌医科大学所属の人しか入っていないが、単施設で3万枚もどうやって集めたのだろうか。医局員がトップの号令の元に作業を行っていたというのが一番予想しやすいが、
あるいは、実は電子化されており顕微鏡画像データがすでに蓄積されていた等なのかもしれないが、方法を知りたいものである。
大腸内視鏡病変検出・鑑別診断
先に述べた2つの例は、レントゲンまたは顕微鏡画像というモダリティであるが、今度は内視鏡画像を機械学習で処理した研究を挙げてみる。
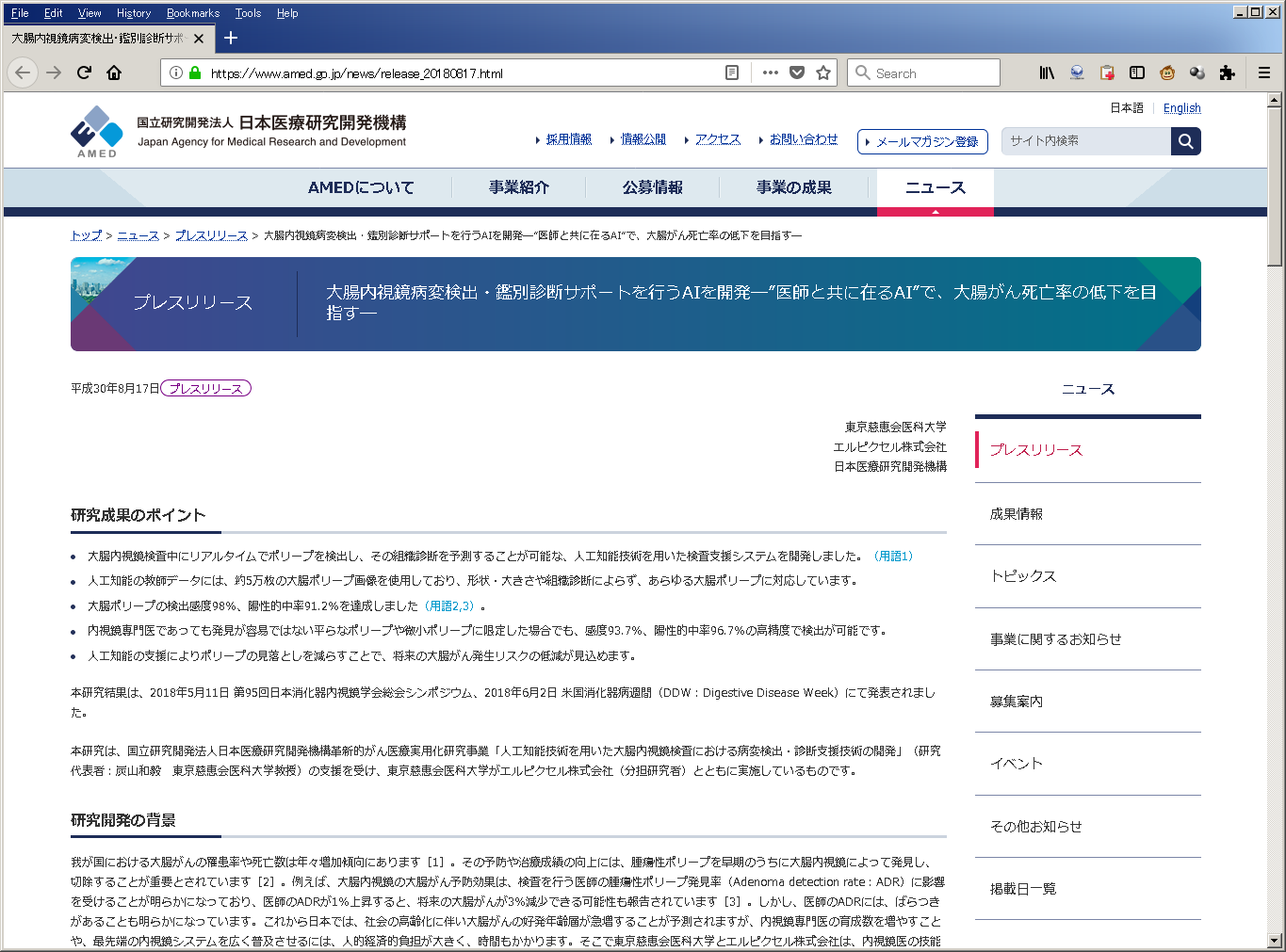
大腸内視鏡病変検出・鑑別診断サポートを行うAIを開発 医師と共に在るAI で、大腸がん死亡率の低下を目指す 2018年8月17日
研究成果のポイント
- 大腸内視鏡検査中にリアルタイムでポリープを検出し、その組織診断を予測することが可能な、人工知能技術を用いた検査支援システムを開発しました。
- 人工知能の教師データには、約5万枚の大腸ポリープ画像を使用しており、形状・大きさや組織診断によらず、あらゆる大腸ポリープに対応しています。
- 大腸ポリープの検出感度98%、陽性的中率91.2%を達成しました。
- 内視鏡専門医であっても発見が容易ではない平らなポリープや微小ポリープに限定した場合でも、感度93.7%、陽性的中率96.7%の高精度で検出が可能です。
- 人工知能の支援によりポリープの見落としを減らすことで、将来の大腸がん発生リスクの低減が見込めます。
本研究結果は、2018年5月11日 第95回日本消化器内視鏡学会総会シンポジウム、2018年6月2日 米国消化器病週間(DDW: Digestive Disease Week)にて発表されました。
本研究は、国立研究開発法人日本医療研究開発機構革新的がん医療実用化研究事業「人工知能技術を用いた大腸内視鏡検査における病変検出・診断支援技術の開発」(研究代表者:炭山和毅 東京慈恵会医科大学教授)の支援を受け、
東京慈恵会医科大学がエルピクセル株式会社(分担研究者)とともに実施しているものです。
国立研究開発法人日本医療研究開発機構(AMED)
データ収集は東京慈恵会医科大学の方でやって、データ処理はエルピクセルに丸投げしたと思われるが、実際に使ったアルゴリズム等は不明で、どこを探しても出てこないので、今後も出てくることはないだろう。
この会社は、2014年の創業当時は、研究室等から様々な画像処理案件を請け負っていたようだが、技術が認められるとともに段々大きな案件を得られるようになって、今回この研究を受けたのだと思われるが、
いったいいくら位で受けたのだろう。AMEDの研究なので、情報公開制度等を利用すれば具体的な金額が出て来ると思われるが、やや手間がかかるので、アカデミック側の予算を調べてみる。
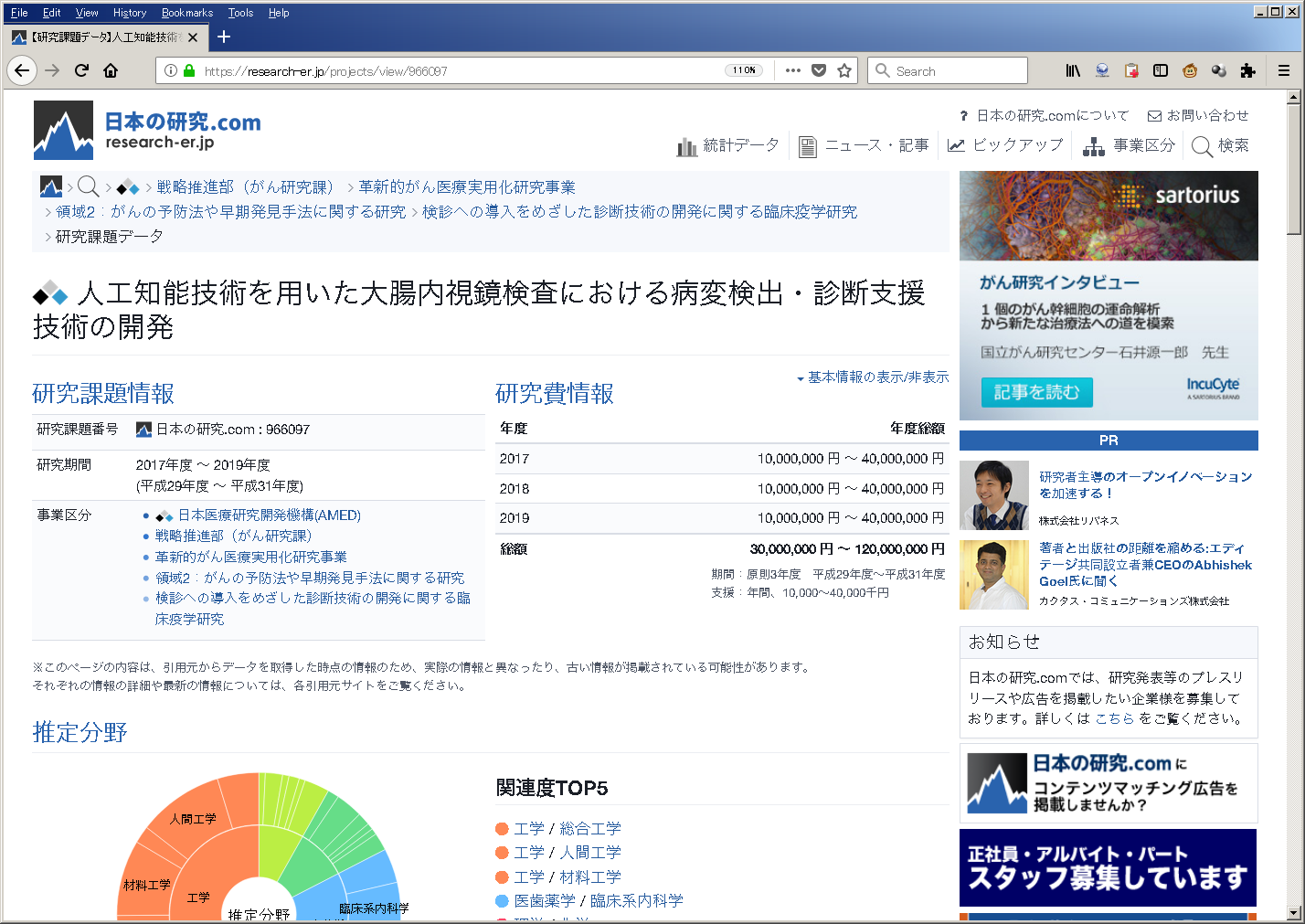
人工知能技術を用いた大腸内視鏡検査における病変検出・診断支援技術の開発 @日本の研究.com
戦略推進部(がん研究課) 革新的がん医療実用化研究事業 領域2
がんの予防法や早期発見手法に関する研究 検診への導入をめざした診断技術の開発に関する臨床疫学研究
研究課題番号 研究課題ID 966097
研究期間 2017年度 ~ 2019年度
(平成29年度 ~ 平成31年度)
事業区分
AMED 日本医療研究開発機構(AMED)
戦略推進部(がん研究課)
革新的がん医療実用化研究事業
領域2:がんの予防法や早期発見手法に関する研究
検診への導入をめざした診断技術の開発に関する臨床疫学研究
年度 年度総額
2017 10,000,000 円 ~ 40,000,000 円
2018 10,000,000 円 ~ 40,000,000 円
2019 10,000,000 円 ~ 40,000,000 円
総額
30,000,000 円 ~ 120,000,000 円
研究期間 2017年度~2019年度 (H.29~H.31)
配分総額 30,000,000 円 ~ 120,000,000 円
プロジェクトメンバー 代表 炭山和毅 学校法人東京慈恵会医科大学
2017年度(H.29) 医歯薬学 / 臨床系外科学
工学 / 人間工学 開発のプロセス 内視鏡治療機器 大腸内視鏡検査 ヒルシュスプルング病 新規医療機器
予算金額の公表データでは、幅のある金額で年1千万から4千万になっており、この会社への委託費が初年度の予算の半分として、間接経費を無視して年2千万の場合1千万となる。
この金額が高いか安いかの評価は非常に難しいところで、どの程度のソフトウエアまで持って行ったかによるので一概には言えないが、発表の写真にあるソフトの程度ならちょっと高いとは思う。
データが揃っていれば、1週間もあれば機械学習や評価が済むので、その仕事の早さで行けば、研究を始めて次の年にそれなりの結果を発表できるのは至極あたりまえと言える。
この研究者が以前に機械学習をテーマとした発表をしたことはないようなので、金(予算)で買うことの出来た技術が大きな力を果たしたと言える。
統計に例えて言えば、絶対に差があると分かっている研究結果データが揃っているのに、差を示すための統計方法が分からないが、その方法を知っている専門家はすでに世の中にいるような状態で、
その専門家に委託する金さえあれば良いような状態だったろう。それに比べると、自分で機械学習を勉強して処理し、発表にまで持って行った井上謙一氏には頭が下がる。
次は別のグループによる、同じ大腸内視鏡の機械学習による認識に関する発表を挙げる。
薬機法(PMDA)が絡むと高額になる
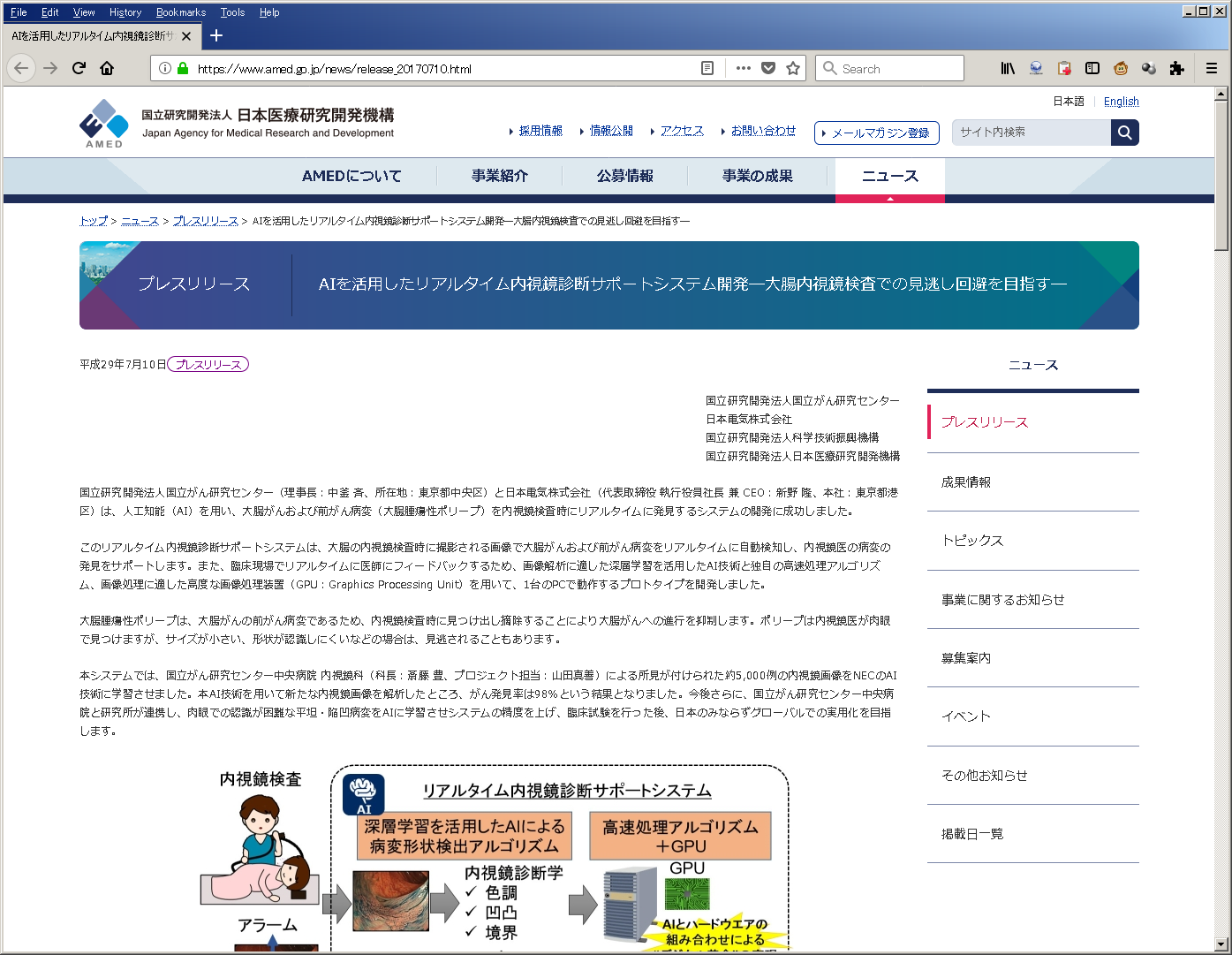
AIを活用したリアルタイム内視鏡診断サポートシステム開発大腸内視鏡検査での見逃し回避を目指す 2017年7月10日
国立研究開発法人 国立がん研究センター
日本電気株式会社
国立研究開発法人科学技術振興機構
国立研究開発法人日本医療研究開発機構
国立研究開発法人国立がん研究センター(理事長:中釜斉、所在地:東京都中央区)と日本電気株式会社(代表取締役執行役員社長兼CEO:新野隆、本社:東京都港区)は、人工知能(AI)を用い、
大腸がんおよび前がん病変(大腸腫瘍性ポリープ)を内視鏡検査時にリアルタイムに発見するシステムの開発に成功しました。
このリアルタイム内視鏡診断サポートシステムは、大腸の内視鏡検査時に撮影される画像で大腸がんおよび前がん病変をリアルタイムに自動検知し、内視鏡医の病変の発見をサポートします。
また、臨床現場でリアルタイムに医師にフィードバックするため、画像解析に適した深層学習を活用したAI技術と独自の高速処理アルゴリズム、画像処理に適した高度な画像処理装置
(GPU:Graphics Processing Unit)を用いて、1台のPCで動作するプロトタイプを開発しました。
大腸腫瘍性ポリープは、大腸がんの前がん病変であるため、内視鏡検査時に見つけ出し摘除することにより大腸がんへの進行を抑制します。ポリープは内視鏡医が肉眼で見つけますが、サイズが小さい、形状が認識しにくいなどの場合は、見逃されることもあります。
本システムでは、国立がん研究センター中央病院内視鏡科(科長:斎藤豊、プロジェクト担当:山田真善)による所見が付けられた約5,000例の内視鏡画像をNECのAI技術に学習させました。
本AI技術を用いて新たな内視鏡画像を解析したところ、前がん病変としてのポリープと早期がんの発見率は98%という結果となりました。今後さらに、国立がん研究センター中央病院と研究所が連携し、
肉眼での認識が困難な平坦・陥凹病変をAIに学習させシステムの精度を上げ、臨床試験を行った後、日本のみならずグローバルでの実用化を目指します。
研究成果 - リアルタイム内視鏡診断サポートシステムの特徴
大腸がんおよび前がん病変の内視鏡の静止画像および動画を対象として解析を行いました。これまでに約5,000例の大腸がんおよび前がん病変の内視鏡画像を学習データとして、NECの最先端AI技術群「NEC the WISE」を用いて解析を行いました。
内視鏡医の観点から内視鏡所見を教示し、画像解析に適した深層学習を活用したAI技術、独自の高速処理アルゴリズム、画像処理に適したGPUを用いて、1台のPCで動作するプロトタイプを開発しました。
システムの性能
ポリープ検出
今回開発したプロトタイプを使用して、新たな約5,000枚の内視鏡画像を評価したところ、前がん病変としてのポリープと早期がんの発見率98%という高い認識性能を有することが明らかになりました(偽陽性率は1%に抑えられています)。
処理時間の高速化
動画各フレームにおける検知と結果表示を約33ミリ秒以内(30フレーム/秒)で行うリアルタイム化に成功しました。これにより、開発したプロトタイプを用いて、実際の診療にてリアルタイムで医師にフィードバックすることが可能となります。
今後の目標
国立がん研究センター中央病院内視鏡科(科長:斎藤豊)に蓄積される1,600例以上の肉眼では認識が困難な平坦・陥凹性病変をAIに学習させ、プロトタイプの精度を上げます。
画像強調内視鏡に代表される新しい内視鏡を利用することにより、大腸ポリープの表面の微細構造や模様を学習し、大腸ポリープの質的診断や大腸がんのリンパ節転移の予測への対応も目指します。
CT画像や分子生物学的情報などの情報とリンクさせ、より利用価値の高いマルチモダリティなリアルタイム内視鏡画像診断補助システムを目指します。
国立がん研究センター研究所・新研究棟4階に設置されたAI解析エリア(GPGPUクラスタ、注2)と中央病院内視鏡科の録画サーバーを、隔絶された閉鎖系VLAN(注3)で接続し研究を加速させます。
こちらは、東京慈恵会大学のグループより一足先に発表した記事だが、こちらでもアルゴリズムの詳細は一切不明で、NEC the WISEとかいう機械学習のソフトウエア商品の広告みたいになっている。
この研究の予算はどの程度であろうか。研究代表が他の研究の共同研究者として予算を一部もらったりしていることもあるのでわかりにくいところがあるが、大まかには下記のような予算と思われる。
大腸前がん病変である鋸歯状病変の内視鏡診断学確立のための研究 基盤研究(C) 推定分野
研究期間 2018年度~2020年度 (H.30~H.32) 配分総額 4,290,000 円
当時の所属 国立研究開発法人国立がん研究センター その他部局等 その他
山田 真善
消化管がんに対する特異的蛍光内視鏡の開発とその臨床応用に向けた研究
戦略推進部(がん研究課) 革新的がん医療実用化研究事業 領域4:患者に優しい新規医療技術開発に関する研究
研究期間 2014年度~2016年度 (H.26~H.28) 配分総額 69,000,000 円
当時の所属 国立がん研究センター 中央病院 内視鏡科 医員
代表者 斎藤豊 独立行政法人 国立がん研究センター 中央病院 内視鏡科
成果の概要
浦野泰照教授(東京大学大学院)らのグループ、尾野雅哉(国立がん研究センター研究所)らのグループ、光永眞人(慈恵会医科大学)らのグループと当内視鏡科で、
我々で開発した蛍光内視鏡技術を用いた、がんの早期発見の臨床評価を行い、微小転移の術中診断や特異的治療への応用を行った。
1)早期がんに特異的な膜タンパク抗原の探索(尾野ら)
新規『蛍光プローブ』の開発に向けて、プロテオーム解析技術 2DICAL を用い、早期大腸がんに特異的な膜タンパク抗原の探索を行った。5975 タンパク質が検出され、
正常粘膜、腺腫、がんにおけるタンパク質量の変動を 9 パターンに分類し、統計学的手法を用いて腺腫の段階から変動するタンパク質を選別し、複数の変動タンパク質を同定した。
2)新規『蛍光プローブ』の開発 (浦野ら)
様々ながん細胞で発現亢進している GGT 活性を検出し、「がん細胞」だけを光らせる新規『蛍光プローブ』を開発し、表面型大腫瘍の内視鏡切除検体を用いて GGT 蛍光活性を確認した。
また早期胃癌の内視鏡切除検体を用いて、非腫瘍部位に特徴的なアミノペプチダーゼ様酵素活性を確認した。
3)ALA 内服蛍光観察による消化管癌の早期発見と術中診断への応用(斎藤・曽ら)
ALA 内服後患者の蛍光観察において、表面型大腸腫瘍に対する Pilot 研究では、82%の赤色蛍光が確認され、内視鏡的に早期癌の診断が可能なことが明らかとなり英語論文化した。
本技術を応用し、進行がんの外科手術において腹膜播種やリンパ節転移の術中リアルタイムイメージングが可能となれば外科手術に革新をもたらす。プロトコールを作成し研究準備を進めている。
4)特異的蛍光内視鏡技術を用いた特異的治療(光永ら)
蛍光プローブ IR700 とがん分子標的特異的モノクローナル抗体を用いて、新たな癌特異的光線治療法(PIT)を開発し、臨床前試験としての基礎研究を行ってきた。
消化管癌に対する内視鏡 PIT の応用化を目標とし た PIT の効果を補完するための新たな治療法として bifunctional monoclonal antibodydrug/photoabsorber conjugates を開発しその有用性について報告した。
5)消化管腫瘍に対する共焦点レーザー顕微内視鏡を用いた Optical biopsy(斎藤・阿部ら)
胃癌・大腸上皮性腫瘍の共焦点レーザー顕微内視鏡画像と病理組織診断との対比を行い、胃病変の良悪性診断、大腸上皮性腫瘍の深達度診断に対する 40 例の pilot 究を行い安全に関して証明した。
機器は製造承認がおりているが本検査に必須のフローレセン静注については眼底検査のみ保険が収載されている。そこで、胃腫瘍に対する共焦点レーザー顕微内視鏡の診断能に関する多施設前向き研究を、
国立がん研究センターで最初の国家戦略特区としての先進医療 B で行い有効性が認められた場合は、消化管領域での保険収載を目指す。すでに厚労省研究開発科との事前相談を2回終え、準備が整った。
6) 形態情報定量化を基盤とした革新的自動診断システムを用いた大腸がんおよび前がん病変発見のための Real-time 内視鏡画像自動解析システムの新規開発(山田・斎藤ら)
約 2500 個の大腸ポリープ等の病変部画像を用いて、病変部特徴量を出力するように多層ニューラルネットワークによる深層学習を行い、病変検知を行うソフトウエアを構築した。
さらに、病変のリアルタイム検知処理を行うために、検知を高速に実行する手法を開発した。この手法と GPU(Graphics ProcessingUnit)を搭載した PC を組み合わせることにより、
内視鏡動画像をリアルタイムで病変検知可能か検討した。主要なアルゴリズムについて特許申請した。今後は臨床での実用化に向けてさらなるデータ集積・解析を行い、診断性能の改善を行う。
1番目のテーマは金額が安くあまり該当せず、2番目にあたると思われるが、金額的には先に挙げた東京慈恵会大学のグループの予算よりやや安い程度である。
プレスリリースも貼ってあるのでこちらと思われる。NECはどの程度の予算で受けたのだろうか。
斎藤豊氏が共同研究者に入っている他のテーマを当たってみると、下記が見つかる。
大腸がん抑制を可能とする、人工知能にもとづく内視鏡診断支援ソフトウェア
事業を横断した取り組み Medical Artsの創成に関する研究 分野3 医療機器開発 情報通信技術(ICT)等を用いた医療支援を行うためのソフトウェアの開発
研究期間 2016年度~2018年度 (H.28~H.30) 配分総額 150,000,000 円(最大)
代表者 工藤進英 昭和大学
斎藤豊 国立がん研究センター 中央病院 内視鏡科 - 2016年度(H.28)
成果の概要
コンピュータ支援内視鏡診断システムの研究開発
(ア)研究開発項目 診断アルゴリズムの改良
名古屋大学森健策研究室
で新規アルゴリズムの検討を行った。従来のソフトウェアではテクスチャ解析に Support Vector Machine を組み合わせて約 90%の正診率であった。
一方新規アルゴリズムはディープラーニングの一種である Convolutional Neural Network (CNN)とテクスチャ解析を組みあわせた。
(イ)研究開発項目 PMDA による対面助言内容を反映した前向き試験用ソフトウェアの完成
2016 年 2 月 29 日に施行した PMDA による対面助言内容を反映しソフトウェアが「自動診断」するのではなく医師に対する「診断支援」
と解釈できる画面のインターフェースを作成し診断アルゴリズムを搭載した試験用ソフトウェアを完成させた。完成した試験用ソフトウェアは昭和大学横浜市北部病院で動作検証を行い、
不具合が無いことを確認し、次年度に行なう多施設共同研究先の臨床試験に備えた。
(ウ)研究開発項目 機械学習の精度向上のための、大規模データベースを作成
各年度 5,000 セットのデータベース作成および診断能 0.5%/年の上昇の目標に対して、本委託研究開発契約開始後に昭和大学横浜市北部病院より随時内視鏡画像の提供を受け、
約 17000 セットの内視鏡画像から機械学習を行い、既存登録の 6,300 セットと合わせ約 20,000 セットのデータベース(学習モデル)を構築した。
臨床研究
(カ)研究開発項目 PMDA薬事戦略相談(対面助言)
PMDAによる薬事戦略相談(対面助言)にて、相談区分が「性能(1試験)」に決定し「後ろ向き試験」による臨床研究による臨床試験が妥当であるとの助言を受け、試験結果を薬機承認申請資料として利用できることを確認した。
(キ)研究開発項目 臨床研究プロトコルの作成
PMDA との対面助言を通じ、臨床研究プロトコルを完成させた。臨床研究の分担施設については、国立がん研究センター中央病院、国立がん研究センター東病院、静岡県立静岡がんセンター、
東京医科歯科大学との再委託契約をすませ、当初予定していた 5 施設での臨床研究を実施可能な状況となった。データセンターについてはイーピーエス株式会社
(医薬品・医療機器開発業務受託機関)と正式に契約し、対面助言の準備・H29 年度の臨床研究の準備を共同で行っている。昭和大学は予定通り H28 年度に倫理委員会の承認が得られた。
今回初めて知ったが、工藤進英氏は内視鏡の分野では非常に有名であるようだ。ここの報告書にはNECの名前はなく、名古屋大学森健策研究室の名前があり、ソフトウエアが出来ているようだが、
特にプレスリリースはないようである。予算配分は上記のいずれよりも高く、3年で1億5千万、年額で最大5千万となっており、研究代表者のネームバリューの重要さが感じられる。斎藤豊氏が共同研究者に入っているが、先の発表とはまた別のようである。
詳細は不明だが、幾ばくかの予算はもらっていると思われ、もしかしたら発表していないだけで、NECにも予算は流れているかもしれない。
こちらのグループの研究では、薬機法下に承認されるソフトウエアとして出す予定のようで、PMDAの助言等を受けているようであるが、対面助言は一回数百万でかなり高く、10回行くと数千万かかることになる。
データセンタの委託費も数千万単位でかなり高額であり、技術というよりその周辺に非常にお金がかかる。
選択と集中と掲げながら、データも方法論もほぼ同一の研究テーマにこのように別々に予算を投じるのは明らかに無駄であるし、同じ研究チームとして日本全国でデータを集めて処理をまとめた方がよっぽど良い結果が出ると思われるが、
そうなっていないのは研究予算申請の審査がそれほどうまくいっていないからだろう。
先に挙げた自分で機械学習を学び診断ソフトウエアを開発している井上謙一氏は、崇高な理念に基づいて無償で技術を還元しようとしており、そこから何らかの追加の対価が生じる可能性は低い。
それに対し、大腸内視鏡の診断ソフトウエアを開発している企業は、対価を得て研究を請け負っており、さらに将来的には、研究終了後にそこからさらなる対価を得られる可能性もある。いわば対極にあるといえるだろう。
インターネットの発達により、技術を学ぶ障壁が比較的低くなり、オープンソフトウエアという形でも技術が無償で手に入るようになることで、自分で技術を集めて学べる人は対価を払うことなく技術を使用出来るようになり、
お金を払う代わりに自分の学習能力で技術を高めていくことができる。しかし、個人でできることは限られているので、同じ課題を解いている場合には、さらに多くの対価を技術に対して払える人との競争が必然的に生じ、
結局は、個人に内在する能力とか、お金の競争というところになり、お金がある場合は、自分でやることと対価を払う部分とのマネジメントの問題になってくる。
無償で技術が得られるようになった場合、段々と同じ技術を持った人が増えてしまうことから、その分野の対価が下がってしまうことが多い。
10年程度もすれば、機械学習の分野にも当てはまっている可能性が高い。
その意味で、エルピクセルは所有技術の対価の未来性をうまく見定めて、比較的高い時にうまく起業したといえるが、今後の機械学習や画像処理の広まりにどう対応していくのだろうか。
対価を生み出す物を見定めて、新しい技術を継続的に取り入れ続けること自体が技術を要することと思われるが、その様な技術とは一体何だろうか。
<rindolf> What should I do now?
<rindolf> I'll work on Text-Qantor.
<rindolf> It's so great not to have a job.
<Zuu> yeah, if someone else pays for the food it sure is :D
<Zuu> also, i dont really understand much of what you just told me
:P
* Zuu puts a stick into the Text-Qantor
<rindolf> Zuu: Qantor == Qantor ain't no TeX/Troff oh really.
<rindolf> It's a typesetting system I'm working on.
* Zuu hates the name
<Zuu> it makes me kinda mad actually :/
<rindolf> Zuu: :-)
<rindolf> Zuu: maybe it will grow on you.
<rindolf> Zuu: some people I know named a browser suckass.
<Zuu> :(
<rindolf> I refused to work on it.
<Zuu> see that's a name!
<rindolf> Zuu: heh.
<Zuu> i didnt mean that btw :)
<Zuu> suckass is kinda... unkind
<rindolf> OK, now I should write an
http://www.shlomifish.org/humour/bits/facts/XSLT/
transformation.
<rindolf> I'll start from something I already have.
<Zuu> But the "X ain't no <something related>" is just a lame naming
convention imho
<Zuu> yeah, work on some XSLT facts :D
<rindolf> Zuu: just call it Qantor then.
<rindolf> Without the mnemonics.
<Zuu> but anyone interrested will learn that it's an abbreviation
<Zuu> just by the fact that it's recursive makes me want to kill
myself a little bit more :P
<rindolf> Zuu: do me a break and kill yourself.
<Zuu> :>
<rindolf> Less Zuus - more grass for evil reindeers like me to feed on.
-- What is Qantor?
-- ##programming, Freenode
<rindolf> What should I do now? Use printf's?
<rindolf> Talking about retro.
<dionisos> no. write an info-bot.
<rindolf> a gdb info-bot?
<dionisos> sure.
-- #svn, Freenode
Powered by UNIX fortune(6)
[
Main Page ]