
RでのROC AUC解析で使ったデータセットを用いて、Python scikit-learnで機械学習をやってみる例。Jupyterが使いやすいのでおすすめ。
非常に有名なアヤメのデータの処理から。
import sklearn
from sklearn import datasets
from sklearn.datasets import load_iris
iris = datasets.load_iris()
# print(type(iris))
print(iris['DESCR'])
print(iris['data'][0:6,])
print(iris['target'])
# Python 3
# Non-exhaustive cross-validation / Holdout method
import sklearn
from sklearn.linear_model import LogisticRegression,PassiveAggressiveClassifier,RidgeClassifier,SGDClassifier
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier,RandomForestClassifier, BaggingClassifier
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier,ExtraTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.decomposition import TruncatedSVD
from sklearn.model_selection import cross_val_score,train_test_split
iris = datasets.load_iris()
features = iris.data
labels = iris.target
# lsa = TruncatedSVD(3)
# print(lsa)
# reduced_features = lsa.fit_transform(features)
# print(reduced_features.shape)
import pandas as pd
data_frame = pd.DataFrame(index=[], columns=['name','score'])
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=0)
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
# ROC AUC: ValueError: multiclass format is not supported
series = pd.Series([clf_name, score], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
# Multi-layer Perceptron classifier
clf = MLPClassifier(hidden_layer_sizes=(3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
data_frame.sort_values('score',ascending=False)
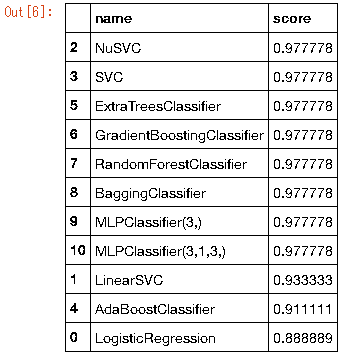
# Stratified K-Folds cross-validation
# Sturges' formula
import math
k = int(1 + math.log(len(labels))/math.log(2))
skf = sklearn.model_selection.StratifiedKFold(n_splits=k,shuffle=True,random_state=0)
print("Number of folds: ", skf.get_n_splits(features, labels))
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
data_frame = pd.DataFrame(index=[], columns=['name','score'])
count = 0
for train_index, test_index in skf.split(features, labels):
count = count + 1
print("[",count,"]",end="")
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
series = pd.Series([clf_name, score], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
view_frame = pd.DataFrame(index=[], columns=['name','score','score std'])
clf_names.append("MLPClassifier(3,1,3,)")
for clf_name in clf_names :
mean = (data_frame[data_frame['name'] == clf_name]['score'].mean())
std = (data_frame[data_frame['name'] == clf_name]['score'].std())
series = pd.Series([clf_name, mean, std], index=view_frame.columns)
view_frame = view_frame.append(series, ignore_index = True)
view_frame.sort_values('score',ascending=False)
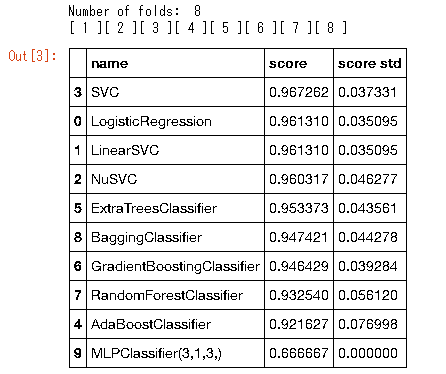
sklearn.model_selection.cross_val_scoreを使うとコードが少なくてすむ。
# sklearn.model_selection.cross_val_score
# Stratified K-Folds cross-validation
# Sturges' formula
import math
k = int(1 + math.log(len(labels))/math.log(2))
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
data_frame = pd.DataFrame(index=[], columns=['name','score','score std'])
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
scores = sklearn.model_selection.cross_val_score(clf,features,labels,cv=k,verbose=1,n_jobs=-1)
series = pd.Series([clf_name, scores.mean(), scores.std()], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
scores = sklearn.model_selection.cross_val_score(clf,features,labels,cv=k)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", scores.mean(), scores.std()], index=data_frame.columns), ignore_index = True)
data_frame.sort_values('score',ascending=False)
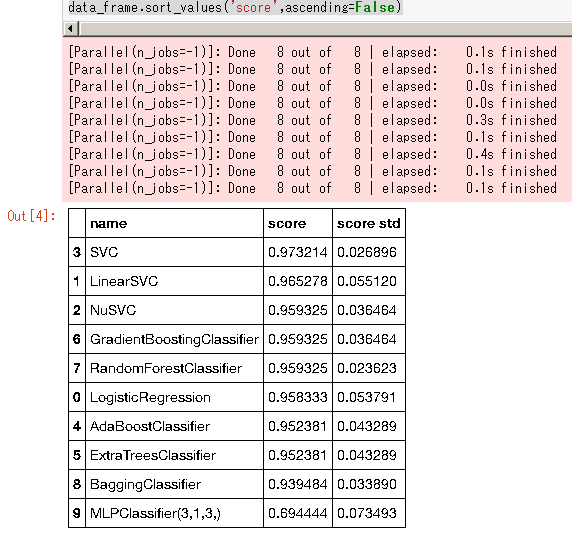
sklearn.model_selection.RepeatedStratifiedKFoldは0.19以上でサポートされたので、古いバージョンでは自前でループを回す必要がある。
# sklearn.model_selection.RepeatedStratifiedKFold
# supported in >= scikit-learn 0.19
# Repeated Stratified K-Fold cross validation
print("sklearn.version", sklearn.__version__)
repeat = 5
import math
k = int(1 + math.log(len(labels))/math.log(2))
print("Number of folds: ", k, " Repeat: ", repeat)
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
data_frame = pd.DataFrame(index=[], columns=['name','score'])
for _ in range(repeat) :
skf = sklearn.model_selection.StratifiedKFold(n_splits=k,shuffle=True,random_state=_*100)
count = 0
for train_index, test_index in skf.split(features, labels):
count = count + 1
print("[",_+1,"-",count,"]",end="")
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
series = pd.Series([clf_name, score], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
view_frame = pd.DataFrame(index=[], columns=['name','score','score std'])
clf_names.append("MLPClassifier(3,1,3,)")
for clf_name in clf_names :
mean = (data_frame[data_frame['name'] == clf_name]['score'].mean())
std = (data_frame[data_frame['name'] == clf_name]['score'].std())
series = pd.Series([clf_name, mean, std], index=view_frame.columns)
view_frame = view_frame.append(series, ignore_index = True)
view_frame.sort_values('score',ascending=False)

matplotlibでscoreのグラフを描画する。
import seaborn
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
X = range(len(view_frame['score'].values))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.barh(X,view_frame.sort_values('score',ascending=True)['score'].values,
xerr=view_frame.sort_values('score',ascending=True)['score std'].values, ecolor='r')
plt.yticks(X, view_frame.sort_values('score',ascending=True)['name'].values)
plt.xlim(0.5, 1.1)
plt.title('Comparisons of Classifiers')
plt.tight_layout()
plt.savefig("scikit-learn0-0.eps")
plt.show()
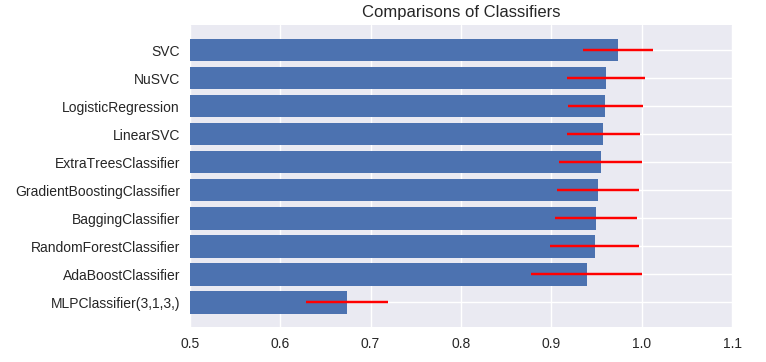
モデル間の比較はpairwise t-testでも良いようだが、ウィルコクソンの符号順位検定(Wilcoxon signed-rank test)を勧める論文(Janez Demšar; JMLR:1--30, 2006.)がある。
# Statistical Comparisons of Classifiers over Multiple Data Sets
# Janez Demšar; JMLR:1--30, 2006.
# "we recommend a set of simple, yet safe and robust non-parametric tests for statistical comparisons of classifiers:
# the Wilcoxon signed ranks test for comparison of two classifiers and
# the Friedman test with the corresponding post-hoc tests for comparison of more classifiers over multiple data sets"
# http://www.jmlr.org/papers/v7/demsar06a.html
from scipy import stats
t, p = stats.ttest_rel(data_frame[data_frame['name'] == 'SVC']['score'],
data_frame[data_frame['name'] == 'AdaBoostClassifier']['score'])
print( "p = %(p)s" %locals() )
t, p = stats.wilcoxon(data_frame[data_frame['name'] == 'SVC']['score'],
data_frame[data_frame['name'] == 'AdaBoostClassifier']['score'])
print( "p = %(p)s" %locals() )
p = 0.000320439029175
p = 0.000945567746743
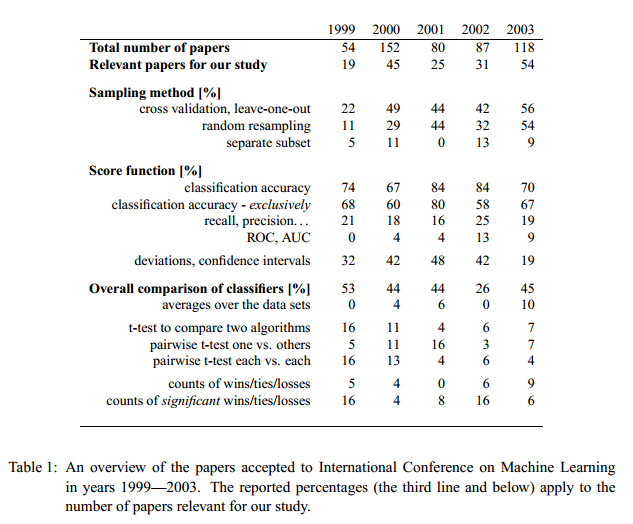
KNeighborsClassifierを例にとって、学習曲線を描画してみる。/だと小数になるので、//で整数を得、np.linspaceでサンプル数を変えて描画させる。
import numpy as np
from sklearn.model_selection import learning_curve
folds = 10
train_sizes, train_scores, valid_scores = learning_curve(KNeighborsClassifier(),
features,labels,cv=folds,
train_sizes=np.linspace(10,len(labels)-len(labels)//folds-1,10,dtype ='int'))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(train_sizes,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(train_sizes,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(train_sizes,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.savefig("scikit-learn8-1.png")
plt.show()
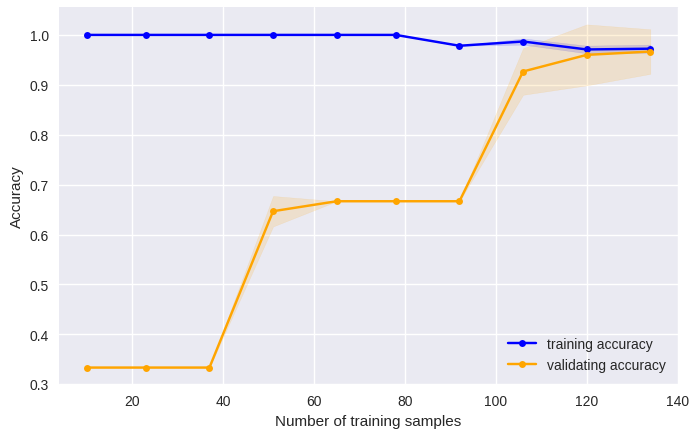
次は自前のデータセットを使ってみる。
データは上記Rでの処理と同じ物を使用。Python pandasが便利。r3-data.cvs
import pandas as pd
df = pd.read_csv("r3-data.csv")
print("len", len(df))
print("shape ", df.shape)
print(df.info())
df.describe()
#df.head(3)
#df.tail(3)
df.iloc[:2]

多変量の場合、C(Inverse of regularization strength)パラメータによりRと同じ値を得る。正則化しない場合、Cに大きな値を入れる。Rで正則化する場合はglmnetを使用する。
vest = df.iloc[:,1].as_matrix()
pdat = df.iloc[:,2:].as_matrix()
X = pdat[:,(0,)] # age
y = vest
clf = LogisticRegression(C=1)
clf.fit(X, y)
print( "ROC AUC (C=1) ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]))
X = pdat[:,(1,2,3,4,)] # x2 A-P MF-AUC x3 L-R MF-AUC x4 A-P Total-AUC x5 L-R Total-AUC
y = vest
clf = LogisticRegression(C=1,penalty='l2',solver='liblinear')
clf.fit(X, y)
print( "ROC AUC (C=1) L2 ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]))
clf = LogisticRegression(C=1,penalty='l2',solver='newton-cg')
clf.fit(X, y)
print( "ROC AUC (C=1) L2 ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]))
clf = LogisticRegression(C=10000)
clf.fit(X, y)
print( "ROC AUC (C=10000) ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]), end="")
print( " <-- without Regularization (= R default output)")
ROC AUC (C=1) 0.558321535315
ROC AUC (C=1) L2 0.871086990719
ROC AUC (C=1) L2 0.869435268208
ROC AUC (C=10000) 0.869592575114 <-- without Regularization (= R default output)
# Non-exhaustive cross-validation / Holdout method
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier
from sklearn.model_selection import cross_val_score
import pandas as pd
features = pdat
labels = vest
data_frame = pd.DataFrame(index=[], columns=['name','score', 'ROC AUC'])
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=0)
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier"]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
if hasattr(clf, 'predict_proba') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])
elif hasattr(clf, 'decision_function') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test))
series = pd.Series([clf_name, score, auc], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
# Multi-layer Perceptron classifier
clf = MLPClassifier(hidden_layer_sizes=(8,8,8,8,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
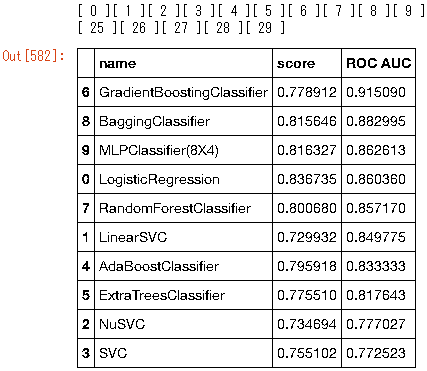
series = pd.Series(["MLPClassifier(8X4)", clf.score(X_test, y_test), sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])],
index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
data_frame.sort_values('ROC AUC',ascending=False)
一般的な統計での操作では、データセットを学習データとテストデータに分けて処理することはない。同じデータで評価した場合、過学習して見た目上良い値が出ることがある。
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier
from sklearn.model_selection import cross_val_score
import pandas as pd
features = pdat
labels = vest
X_train = X_test = features
y_train = y_test = labels
data_frame = pd.DataFrame(index=[], columns=['name','score', 'ROC AUC'])
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier","RandomForestClassifier","BaggingClassifier"]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
if hasattr(clf, 'predict_proba') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])
elif hasattr(clf, 'decision_function') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test))
series = pd.Series([clf_name, score, auc], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
# Multi-layer Perceptron classifier
clf = MLPClassifier(hidden_layer_sizes=(8,8,8,8,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
series = pd.Series(["MLPClassifier(8X4)", clf.score(X_test, y_test), sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])],
index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
data_frame.sort_values('ROC AUC',ascending=False)
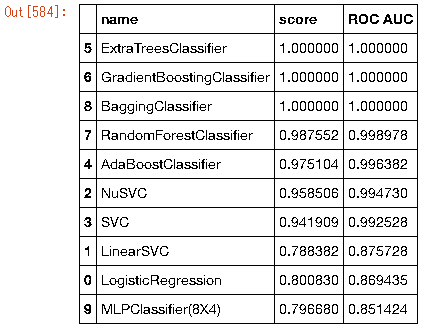
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier
from sklearn.model_selection import cross_val_score
import pandas as pd
features = pdat
labels = vest
# Repeated Stratified K-Fold cross validation
repeat = 5
import math
k = int(1 + math.log(len(labels))/math.log(2))
print("Number of folds: ", k, " Repeat: ", repeat)
data_frame = pd.DataFrame(index=[], columns=['name','score', 'AUC'])
data_sum = pd.DataFrame(index=[], columns=['name','score', 'AUC'])
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier"]
for _ in range(repeat) :
skf = sklearn.model_selection.StratifiedKFold(n_splits=k,shuffle=True,random_state=_*100)
count = 0
for train_index, test_index in skf.split(features, labels):
count = count + 1
print("[",_+1,"-",count,"]",end="")
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
if hasattr(clf, 'predict_proba') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])
elif hasattr(clf, 'decision_function') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test))
series = pd.Series([clf_name, score, auc], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(8,8,8,8,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
series = pd.Series(["MLPClassifier(8X4)", clf.score(X_test, y_test), sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])],
index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
view_frame = pd.DataFrame(index=[], columns=['name','score','score std','AUC','AUC std'])
clf_names.append("MLPClassifier(8X4)")
for clf_name in clf_names :
mean = (data_frame[data_frame['name'] == clf_name]['score'].mean())
std = (data_frame[data_frame['name'] == clf_name]['score'].std())
aucm = (data_frame[data_frame['name'] == clf_name]['AUC'].mean())
aucs = (data_frame[data_frame['name'] == clf_name]['AUC'].std())
series = pd.Series([clf_name, mean, std, aucm, aucs], index=view_frame.columns)
view_frame = view_frame.append(series, ignore_index = True)
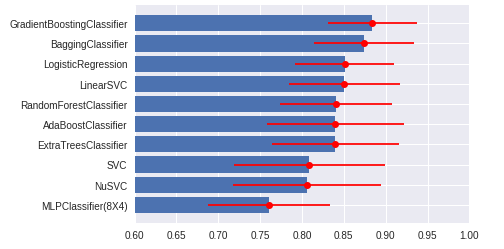
view_frame.sort_values('AUC',ascending=False)

エラーバーつき棒グラフで比較する図を描画
import seaborn
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
X = range(len(view_frame['AUC'].values))
plt.barh(X,view_frame.sort_values('AUC',ascending=True)['AUC'].values)
plt.yticks(X, view_frame.sort_values('AUC',ascending=True)['name'].values)
plt.errorbar(view_frame.sort_values('AUC',ascending=True)['AUC'].values,X,
xerr=view_frame.sort_values('AUC',ascending=True)['AUC std'].values,
fmt='ro', ecolor='r', capthick=1)
plt.xlim(0.6, 1)
plt.show()
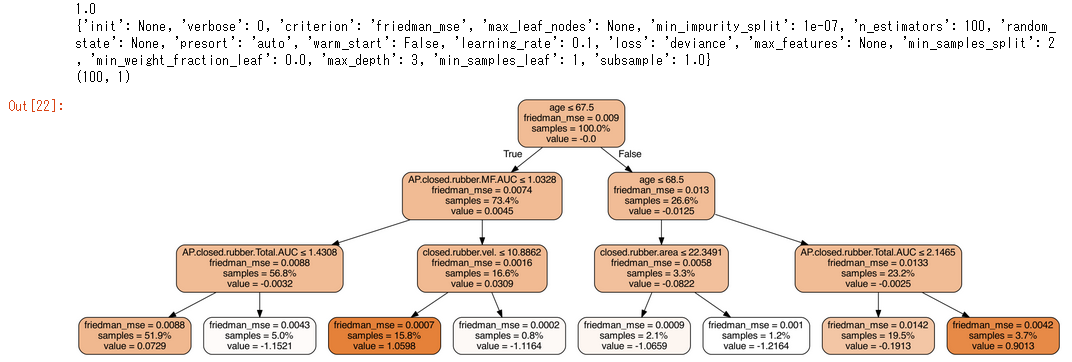
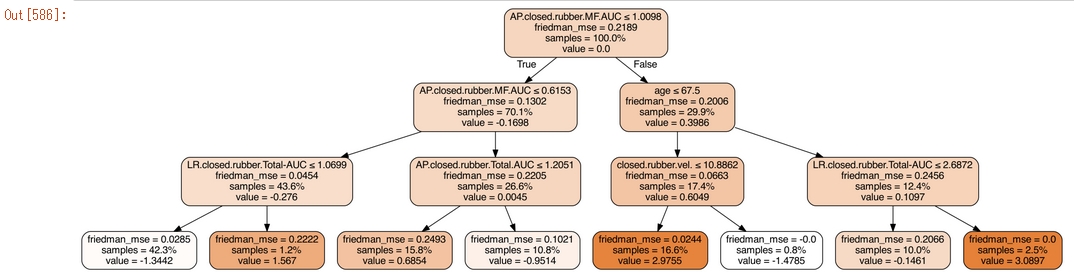
アンサンブル学習(Ensemble learning)では、決定木が複数あるので、すべてを表示して確認するのはあまり意味があることではないが、一部を表示しておおよそを掴むことが出来る。
clf = GradientBoostingClassifier()
clf.fit(X_train, y_train)
print(sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test)))
print(clf.get_params())
print(clf.estimators_.shape)
import pydotplus
from IPython.display import Image
sub_tree = clf.estimators_[99,0]
dot_data = sklearn.tree.export_graphviz(sub_tree, out_file=None, filled=True, rounded=True,
special_characters=True, proportion=True,
feature_names=df.columns[2:] )
Image(pydotplus.graph_from_dot_data(dot_data).create_png())
sub_tree = clf.estimators_[0, 0]
dot_data = sklearn.tree.export_graphviz(sub_tree, out_file=None, filled=True, rounded=True,
special_characters=True, proportion=True,
feature_names=df.columns[2:])
Image(pydotplus.graph_from_dot_data(dot_data).create_png())
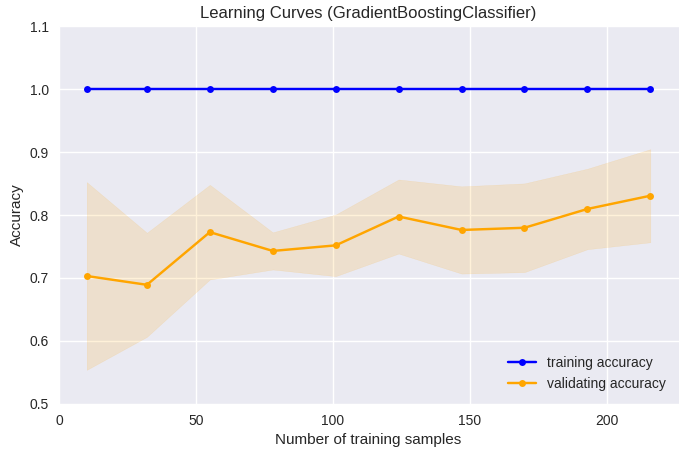
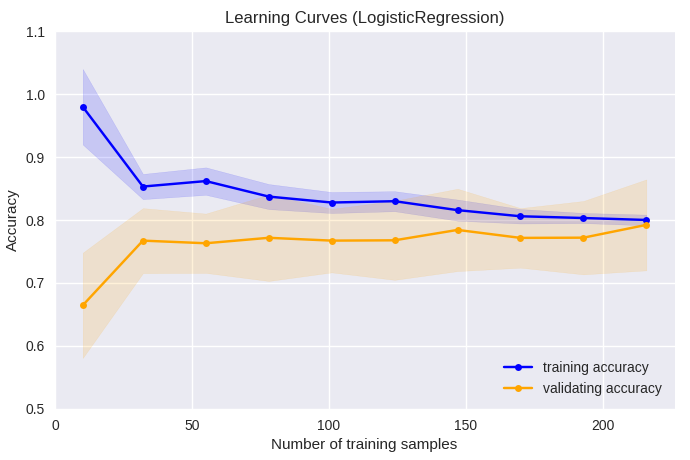
ロジスティック回帰の学習曲線は、標本数が50前後でtraining accuracy及びvalidating accuracyともに約0.8に収束し、 50以上の標本数の追加による大きな予測能の向上は見られなかった。Gradient Boosting Clas-sifierの場合、training accuracyはほぼ1で、 validating accuracyは標本数200を超えても予測能が向上する傾向にあり、過学習の危険性に注意する必要があるが、 標本数の追加によりさらなる予測能の向上が期待でき、モデルの予測能としての能力はロジスティック回帰より高いと考えられた。 誤差のfill_betweenを透過でEPS出力すると正常に描画されないことがあるので、この例では、png出力としている。
import numpy as np
from sklearn.model_selection import learning_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
train_sizes, train_scores, valid_scores = learning_curve(GradientBoostingClassifier(),
features[indices],labels[indices],cv=folds,
train_sizes=np.linspace(10,len(labels)-len(labels)//folds-1,10,dtype ='int'))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(train_sizes,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(train_sizes,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(train_sizes,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.title('Learning Curves (GradientBoostingClassifier)')
plt.legend(loc='lower right')
plt.ylim([0.5,1.1])
plt.savefig("scikit-learn0-10.png")
plt.show()
import numpy as np
from sklearn.model_selection import learning_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
train_sizes, train_scores, valid_scores = learning_curve(LogisticRegression(),
features[indices],labels[indices],cv=folds,
train_sizes=np.linspace(10,len(labels)-len(labels)//folds-1,10,dtype ='int'))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(train_sizes,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(train_sizes,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(train_sizes,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.title('Learning Curves (LogisticRegression)')
plt.legend(loc='lower right')
plt.ylim([0.5,1.1])
plt.savefig("scikit-learn0-11.png")
plt.show()
モデルのパラメータは、それぞれのモデルにおける設定値や制限値であり、パラメータによって予測性能は大きく変わるため、最適なパラメータの決定は重要である。 最適なパラメータを算出する数式等は存在せず、基本的に、経験的方法または、全てのパラメータに様々な値を当てはめて予測性能を算出し最大値を探す探索的方法に基づく。 ロジスティック回帰及びアンサンブル学習において、それぞれの代表的なパラメータの調整により予測能がどの程度変化するか評価した。
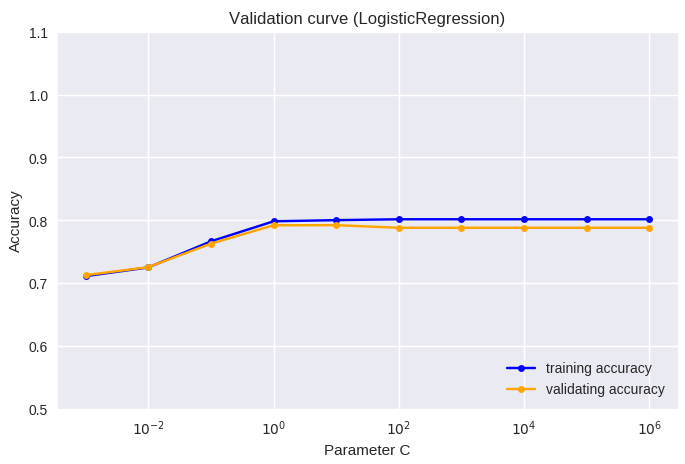
正則化は、過学習を防ぐための手段であり、L1正則化またはL2正則化が比較的多く用いられる。プログラムの既定ではL2正則化が採用されており、 そのパラメータの調節により予測能がどう変化するかを検証曲線にて評価した。本プログラムにおいては、C (Inverse of regularization strength)が小さい時に正則化が強く、 大きな時には正則化が弱い。プログラムの既定のパラメータであるC=1より正則化を強くすると、training accuracy及びvalidating accuracyともに減少し、 過度な正則化はモデルの予測能を下げると考えられた。
from sklearn.model_selection import validation_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
param_range = np.logspace(-3, 6, num=10)
train_scores, valid_scores = validation_curve(LogisticRegression(),
features[indices],labels[indices],cv=folds,
param_name='C',
param_range=param_range)
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(param_range,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.plot(param_range,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.xscale('log')
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.title('Validation curve (LogisticRegression)')
plt.legend(loc='lower right')
plt.ylim([0.5,1.1])
plt.savefig("scikit-learn0-12.png")
plt.show()
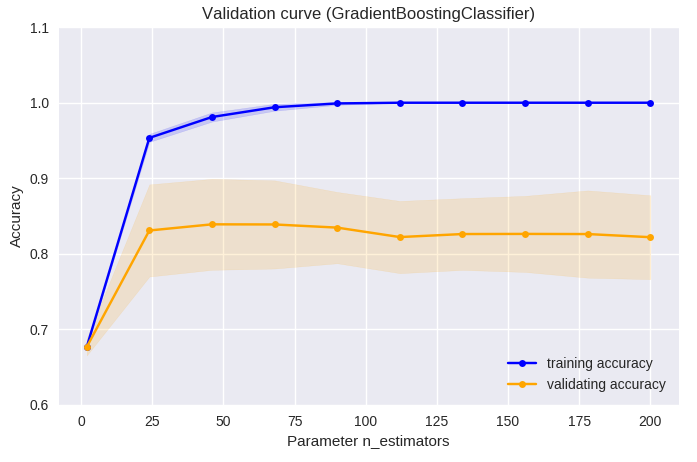
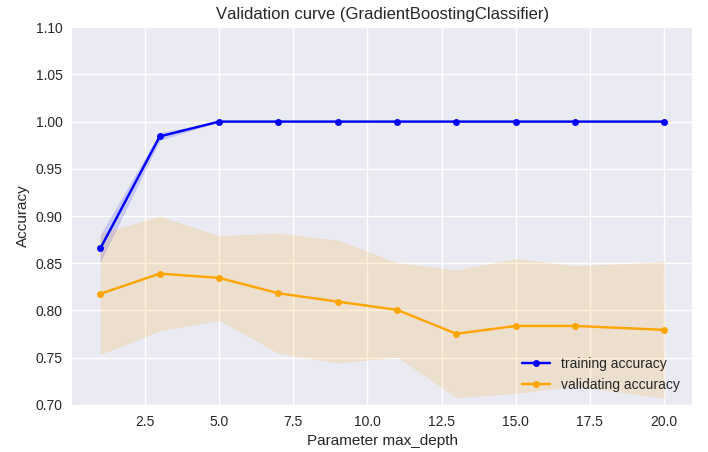
アンサンブル学習は複数の決定木からモデルが作られる。この決定木の数及び深さの調整により予測能がどう変化するか検証曲線にて評価した。 決定木の数については、50前後で予測能が高く、それ以上増やしてもあまり予測能は向上しない傾向にあった。決定木の深さについては、 3前後で最も予測能が高く、それ以上の深さでは予測能が低下する傾向にあった。本データの最適パラメータ探索においては、深さ2、 決定木数45の時に最も予測能が高かったが、プログラムの既定のパラメータである深さ3、決定木数100の時の予測能と有意差はなかった。
from sklearn.model_selection import validation_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
param_range = np.linspace(2,200,10,dtype ='int')
train_scores, valid_scores = validation_curve(GradientBoostingClassifier(),
features[indices],labels[indices],cv=folds,
param_name='n_estimators',
param_range=param_range)
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(param_range,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(param_range,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(param_range,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(param_range,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Parameter n_estimators')
plt.ylabel('Accuracy')
plt.title('Validation curve (GradientBoostingClassifier)')
plt.legend(loc='lower right')
plt.ylim([0.6,1.1])
plt.savefig("scikit-learn0-13.png")
plt.show()
from sklearn.model_selection import validation_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
param_range = np.linspace(1,20,10,dtype ='int')
train_scores, valid_scores = validation_curve(GradientBoostingClassifier(n_estimators=50),
features[indices],labels[indices],cv=folds,
param_name='max_depth',
param_range=param_range)
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(param_range,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(param_range,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(param_range,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(param_range,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Parameter max_depth')
plt.ylabel('Accuracy')
plt.title('Validation curve (GradientBoostingClassifier)')
plt.legend(loc='lower right')
plt.ylim([0.7,1.1])
plt.savefig("scikit-learn0-14.png")
plt.show()
Q: What's buried in Grant's tomb?
A: A corpse.
I'm a Lesbian born in a man's body.
-- Unclear (origin needed)
-- Unknown